Fine-Tuning Mistral-7B with QLoRA for Financial Q&A: A Complete Guide

Table of contents
Introduction
In this blog, we’ll explore how to fine-tune the Mistral-7B language model using QLoRA (Quantized Low-Rank Adaptation) for financial question-answering tasks. This approach enables efficient fine-tuning of large language models while maintaining performance and reducing computational requirements.
What is QLoRA?
QLoRA (Quantized Low-Rank Adaptation) is a parameter-efficient fine-tuning (PEFT) technique that combines two powerful concepts: 4-bit quantization and Low-Rank Adaptation (LoRA). Introduced by Dettmers et al. in 2023, QLoRA enables the fine-tuning of large language models (LLMs) with significantly reduced memory requirements while maintaining a performance quality comparable to full fine-tuning.
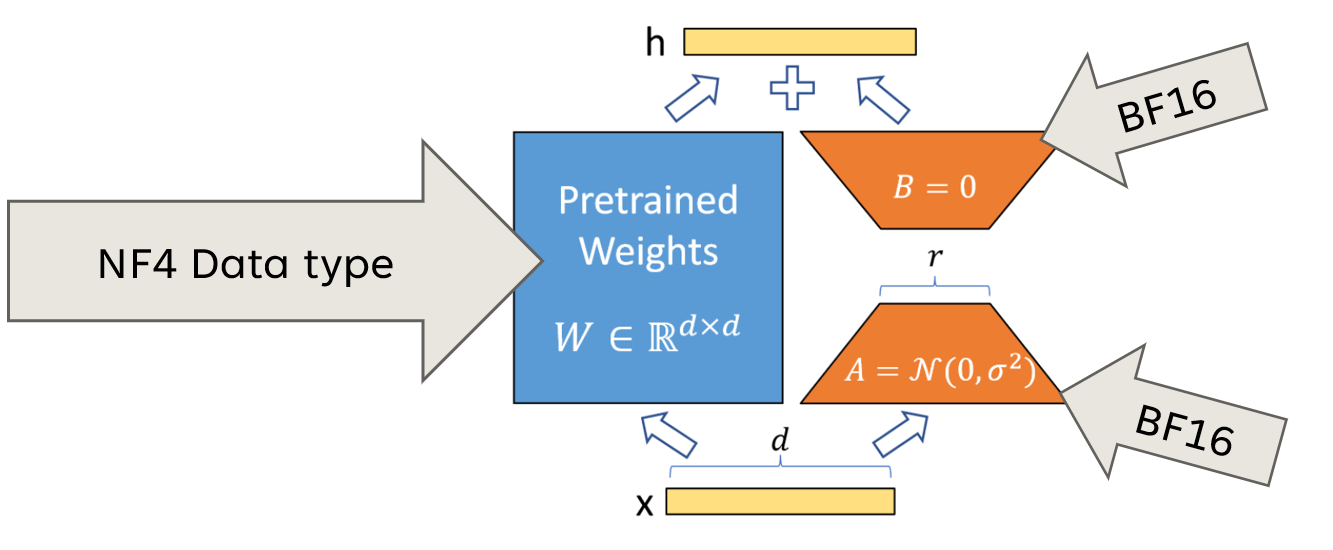
Figure 1: QLoRA (Quantized Low-Rank Adaptation)
Source: NVIDIA Documentation.
Core Components
1. Low-Rank Adaptation (LoRA):
LoRA is based on the hypothesis that the weight updates during fine-tuning have a low “intrinsic rank.” Instead of updating all model parameters, LoRA adds trainable low-rank matrices to the existing frozen weights.
You can find additional information about LoRA in the previous blog post.
2. 4-bit Quantization:
Quantization reduces the precision of model weights from 32-bit floats to lower bit representations. QLoRA uses 4-bit quantization with:
- NF4 (Normal Float 4) Quantization:
- Optimized for Neural Networks: Utilizes a non-uniform quantization scheme
- Information Theoretically Optimal: It aims to minimize quantization error, specifically for normally distributed weights.
- Quantization Bins: Features 16 discrete levels that are optimally configured for neural network weights.
- Double Quantization:
- Further compresses the quantization constants themselves
- ~0.37 bits per parameter instead of 0.5 bits
- Maintains model quality
Why Fine-tune for the Financial Domain?
Financial Q&A requires domain-specific knowledge and terminology. Fine-tuning helps the model:
- Understand financial concepts better
- Provide more accurate and relevant responses
- Maintain consistency in financial advice format
Environment Setup and Dependencies
The first step involves importing essential libraries for the fine-tuning process:
import torch
from datasets import load_dataset, DatasetDict
from peft import LoraConfig, get_peft_model, TaskType
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from trl import SFTTrainer, DataCollatorForCompletionOnlyLM
torch: Core PyTorch library for tensor operations and GPU managementdatasets: Hugging Face library for loading and processing datasetspeft: Parameter Efficient Fine-Tuning library that provides LoRA implementationtransformers: Hugging Face library for pre-trained models and tokenizerstrl: Transformer Reinforcement Learning library with SFTTrainer for supervised fine-tuning
Dataset Loading and Preparation
This step involves loading the financial Q&A dataset and splitting it appropriately:
dataset = load_dataset("FinGPT/fingpt-fiqa_qa")
train_test_split = dataset["train"].train_test_split(test_size=0.1)
dataset = DatasetDict({
"train": train_test_split["train"],
"validation": train_test_split["test"]
})
The FinGPT dataset contains financial questions and answers from various sources. Since the original dataset only has a training split, we create a 90-10 train-validation split. Each example contains instruction, input (question), and output (answer) fields.
The dataset contains examples like:
Instruction: “Utilize your financial knowledge, give your answer or opinion to the input question”Input: “What is considered a business expense on a business trip?”Output: Detailed financial advice about business expenses
Model and Tokenizer Configuration
This is where the magic of QLoRA begins - configuring 4-bit quantization:
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4"
)
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1",
quantization_config=quantization_config,
device_map="auto",
torch_dtype=torch.float16
)
The 4-bit quantization process significantly reduces memory requirements by converting the model’s 32-bit floating-point weights to 4-bit representations, achieving an 87% memory reduction.
This implementation uses NF4 (Normal Float 4) quantization, which is specifically optimized for neural networks and provides better performance than standard 4-bit formats. This step is again optimized with double quantization, which further compresses the quantization constants themselves for additional memory savings.
While the weights are stored in 4-bit format, computations are performed in float16 (half-precision) to maintain a balance between processing speed and numerical accuracy. The system employs automatic device mapping to intelligently distribute model layers across available GPUs, optimizing resource utilization.
The tokenizer configuration includes special tokens for response formatting:
tokenizer = AutoTokenizer.from_pretrained(
model_name,
additional_special_tokens=["<response>", "<response|end>"]
)
model.resize_token_embeddings(len(tokenizer))
Why resize embeddings?
-
New special tokens need corresponding embeddings
-
The model’s vocabulary size must match the tokenizer’s vocabulary size
-
This ensures proper handling of response templates during training and inference
LoRA Configuration
LoRA parameters determine how the model will be fine-tuned efficiently:
peft_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
lora_dropout=0.1,
task_type=TaskType.CAUSAL_LM
)
Understanding LoRA Parameters
LoRA enables efficient fine-tuning by injecting small, trainable low-rank matrices into selected layers of a large model. The rank (e.g., r = 16) controls the dimensionality of these matrices—lower ranks reduce compute and memory usage, while higher ranks improve learning capacity. A value of 16 is often chosen as a sweet spot between efficiency and performance.
The alpha parameter (lora_alpha = 32) scales the adapted weights using alpha / rank, amplifying their impact—commonly set to twice the rank. Target modules specify which layers to adapt, typically the attention projections (q_proj, k_proj, v_proj, o_proj) and MLP components (gate_proj, up_proj, down_proj), where adaptation is most effective.
Dropout adds regularization to avoid overfitting. Overall, LoRA introduces only ~16M trainable parameters (about 0.2% of the original 7B-parameter Mistral model), calculated as rank × (input_dim + output_dim) × num_modules. This makes LoRA a highly efficient fine-tuning technique that preserves model quality with minimal computational overhead.
Data Preprocessing and Formatting
def preprocess_data(example):
prompt = (
f"Instruction: {example['instruction']}\n"
f"Input: {example['input']}\n"
f"<response>{example['output']}<response|end>"
)
return {"text": prompt}
-
Instruction Format: Defines a standardized structure that helps the model understand and learn task prompts consistently. -
Response Template: Special tokens like<response>and<response|end>indicate where the model’s answer should begin and end. -
Training Target: During training, the model is optimized to generate the text that follows the<response>token.
Instruction: Utilize your financial knowledge, give your answer or opinion to the input question or subject.
Input: What is considered a business expense on a business trip?
<response>Business expenses on trips typically include transportation, lodging, meals (subject to limitations), and conference fees that are ordinary and necessary for your business...<response|end>
Loss Configuration
response_template_ids = tokenizer.encode("<response>", add_special_tokens=False)
collator = DataCollatorForCompletionOnlyLM(
tokenizer=tokenizer,
response_template="<response>"
)
Completion-Only Training is a fine-tuning strategy that computes loss only on tokens following the <response> marker, ignoring the instruction and input portions. This allows the model to focus solely on learning how to generate high-quality responses, rather than wasting capacity memorizing prompts or formatting patterns.
Unlike standard causal language modeling—which treats all tokens equally—completion-only training prevents overfitting on instruction templates and encourages the model to generalize better to the task at hand. This leads to faster convergence, reduced training time, and higher-quality outputs, especially in instruction-following tasks like answering financial queries.
By dedicating training solely to the response portion, the model learns to reason and respond more effectively without being distracted by the input scaffolding.
Training Configuration
training_args = TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=16,
learning_rate=5e-4,
num_train_epochs=1,
fp16=True,
gradient_checkpointing=True,
evaluation_strategy="steps",
eval_steps=200,
)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
tokenizer=tokenizer,
peft_config=lora_config,
data_collator=collator
)
The SFTTrainer (Supervised Fine-Tuning Trainer) is a training framework for instruction-tuned fine-tuning of large language models. It integrates PEFT techniques like LoRA, embedding them directly into the model architecture.
Designed for efficiency, it handles advanced training mechanics such as gradient accumulation, checkpointing, and memory optimization—ensuring optimal GPU utilization. Additionally, it tracks validation loss in real time to monitor model performance and mitigate overfitting, making it an all-in-one solution for fine-tuning instruction-following models.
Parameter efficiency:
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Trainable%: {trainable_params/total_params*100:.4f}%")
Total parameters: ~7B
Trainable parameters: ~16M (with r=16)
Trainable percentage: ~0.2%
This demonstrates QLoRA’s efficiency - achieving good performance while training less than 1% of the model’s parameters.
Model Inference and Testing
def infer(instruction, text, model, tokenizer):
input_text = f"Instruction: {instruction}\nInput: {text}\n<response>"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(
**inputs,
max_new_tokens=2048,
do_sample=True,
top_p=0.95,
temperature=0.2,
eos_token_id=tokenizer.convert_tokens_to_ids("<response|end>")
)
When tested with “What is considered a business expense on a business trip?” query:
Input format:
Instruction: Utilize your financial knowledge, give your answer or opinion to the input question or subject.
Input: What is considered a business expense on a business trip?
<response>
Generated response:
The IRS has a list of deductible expenses here. The key thing to remember is that you can only deduct expenses that are ordinary and necessary for your business. If you're going to a conference, then it's probably OK to deduct the cost of the conference itself (assuming it's related to your business)...
This QLoRA implementation represents a significant change in the fine-tuning of large language models. It effectively combines 4-bit quantization with LoRA adaptation.