Inside Qwen3: How Adaptive Thinking Redefines Large Language Models
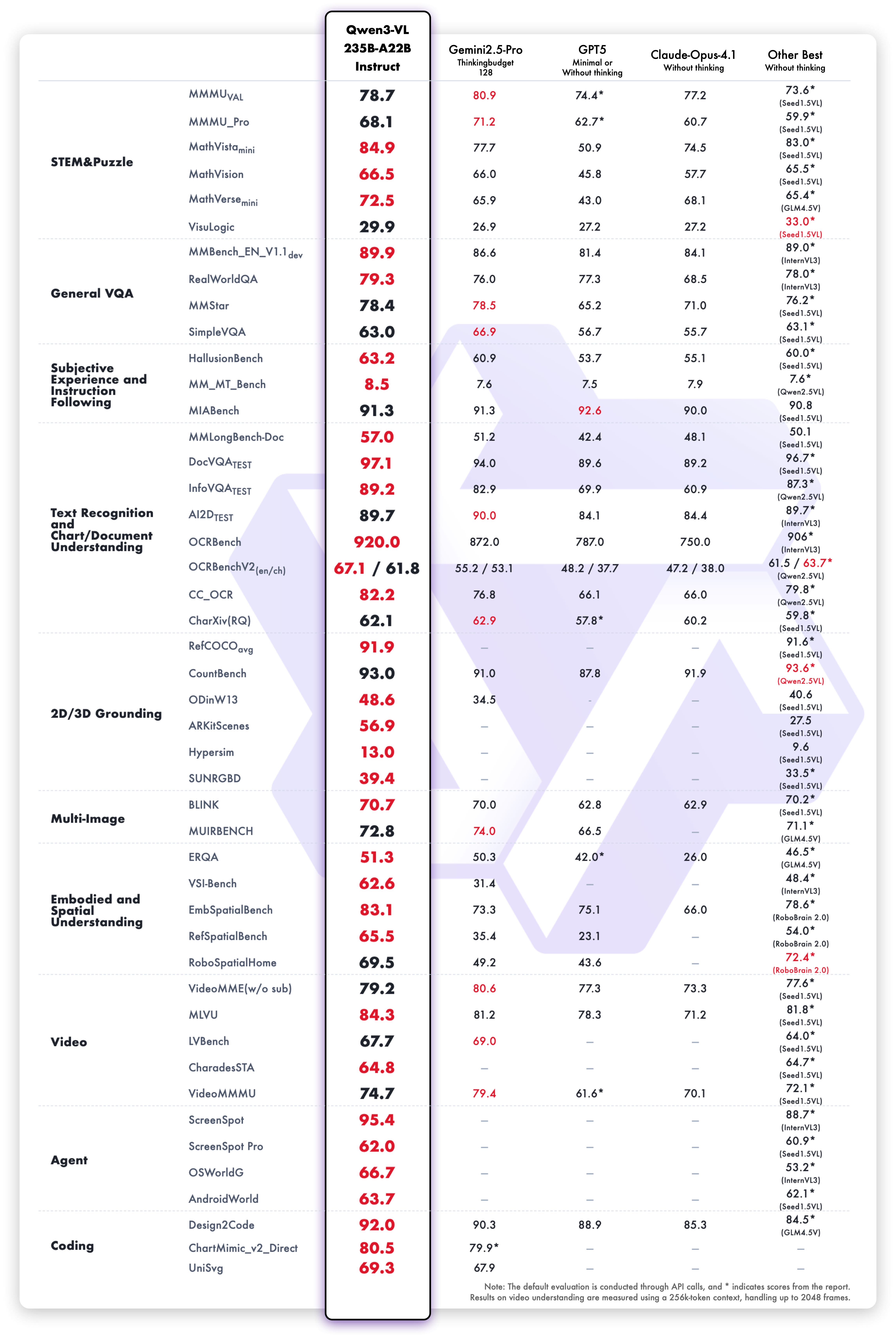
Table of contents
Introduction

Over the past year, the frontier of large language models (LLMs) has shifted from sheer scale toward intelligent efficiency — models that can reason deeply when needed, yet remain fast and lightweight for simpler tasks. Qwen3, the third generation of Alibaba’s Qwen model family, represents this direction. It is not just a bigger model; it’s a smarter and more adaptive one.
According to the Qwen3 Technical Report, the series introduces a unified architecture that supports both “thinking” and “non-thinking” modes within a single framework. This dual-mode design allows Qwen3 to dynamically switch between rapid response generation and deliberate, multi-step reasoning — depending on the complexity of the user’s query. The result is a model that can answer factual questions instantly or engage in extended chain-of-thought (CoT) reasoning for challenging problems like mathematics, coding, and logic.
Qwen3 is available across a wide range of sizes — from small (0.6B) to ultra-large (235B) parameters — in both dense and Mixture-of-Experts (MoE) forms. This scalability makes it suitable for everything from edge deployment to large-scale inference.
Qwen3-VL extends the model into the vision–language domain, giving it the ability to process, reason about, and act on multimodal inputs such as text, images, and layouts. Qwen3-VL emphasizes this expansion as part of Qwen’s goal to create general-purpose, agentic models that “see, think, and act” coherently in complex environments.
In sum, Qwen3 represents a shift from static text models to adaptive reasoning systems — ones that manage their own thinking depth, context budget, and computational resources.
In the rest of this blog, I’ll cover:
- Thinking vs Non-Thinking mode
- The three-stage architecture
- Core concepts (ABF, YARN, post training, long CoT cold start, GRPO, KL divergence)
- Hyperparameters during thinking vs nonthinking
- Examples of Qwen3 in action
Let’s begin.
Thinking vs Non-Thinking Mode
One of Qwen3’s selling point is that it can dynamically switch between two modes:

-
Non-Thinking Mode: Fast, lighter inference. Use this when the user’s prompt is simple or doesn’t need deep reasoning (e.g. “What is the capital of France?”).
-
Thinking Mode: Slower, more deliberate, with chain-of-thought or multi-step reasoning internally. Use this for hard reasoning, math, planning, logic tasks.
The key is that Qwen3 is a single model that supports both modes—unlike some systems that require separate “reasoning models” vs “chat models”.
How switching works conceptually?
Internally, the tokenizer or prompt template will signal the mode. Based on that, the model engages different computational branches or internal attention depths. The thinking mode may use more layers, more internal sampling, more reasoning steps, while non-thinking uses a lighter path.
Qwen3 also implements a thinking budget: the system can allocate how much compute/time is used in thinking mode for a given input. Simpler reasoning gets a smaller budget, harder problems get larger budgets. This helps trade off latency vs reasoning quality.
Because of this, you don’t need two separate models (one optimized for speed, one for reasoning)—one model handles both with mode switching.
In Qwen3-VL, thinking mode also engages more cross-modal reasoning, combining visual and textual cues more deeply.
Three-Stage Architecture
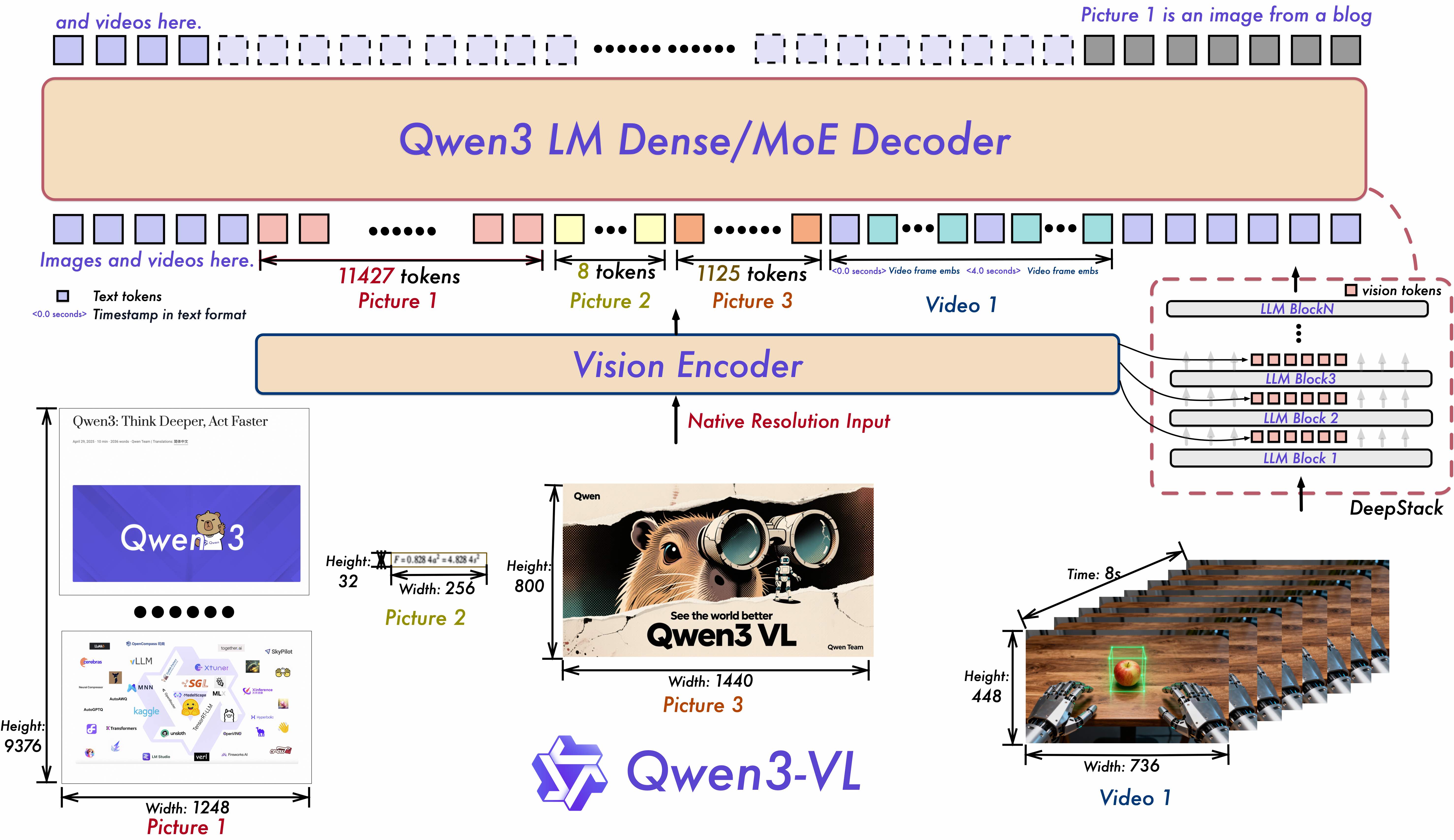
Qwen3’s internal design can be viewed as a three-stage architecture (sometimes described as “stages” of processing). This division helps structure the flow of computation in both modes. Simplified:
-
Stage 1: Shallow encoding / early layers
- Initial token embedding, positional encoding, light attention
- For non-thinking mode, you might stop after stage 1 or stage 2
-
Stage 2: Intermediate representation / routing & experts
- The model decides how much deeper processing is needed
- For MoE variants, here is where routing into experts may happen
-
Stage 3: Deep reasoning / full attention
- Full attention, deeper layers, cross-module reasoning
- Chain-of-thought unfolds here
You can think: in non-thinking, you might only traverse stage 1 → stage 2 partially; in thinking mode, you go all the way through all three, possibly iterating in stage 3 more extensively.
This architecture supports gradual “budgeted” computation: early stopping, selective expert routing, or skipping deeper layers when not needed.
A visual representation (from an open-source writeup) shows how Qwen3 uses mixtures of experts with zero-centered routing and gated attention across layers.
In MoE variants, the routing to experts is embedded in stage 2, deciding which expert(s) to activate for deeper reasoning or specialization.
Core Concepts Explained
Below are the main technical ideas in Qwen3 and related literature.
1. Adjusted Base Frequency (ABF)
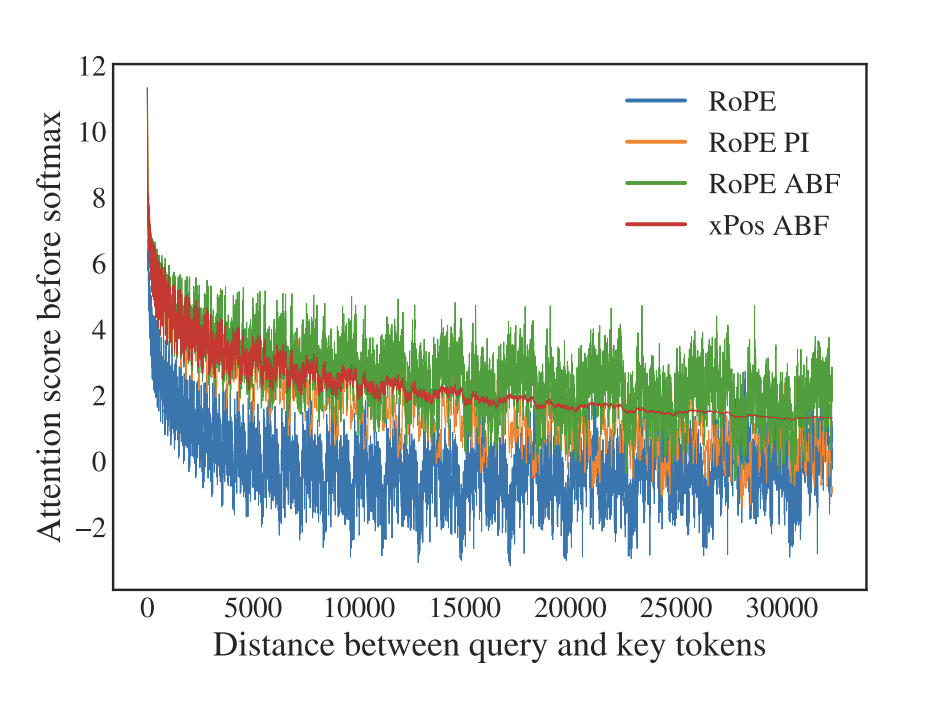
ABF is a key concept utilized in Qwen3 to improve how the model handles thinking mode versus non-thinking mode. It modifies the token sampling frequency and generation rhythm of the model — essentially tuning how often the model “thinks” before emitting the next token.
In large language models, especially those capable of multi-step reasoning, generation can happen in two phases:
- Internal reasoning (hidden CoT phase) — where the model performs silent computation steps, refining intermediate reasoning tokens that aren’t shown to the user.
- Visible response generation — where the model emits the final, polished answer.
The challenge is balancing speed vs depth: reasoning too deeply slows inference, but reasoning too shallowly can hurt accuracy. This is where ABF comes in.
ABF dynamically adjusts the internal token generation frequency based on the model’s operating mode and the complexity of the query:
- In non-thinking mode, ABF keeps the base frequency high — meaning the model generates visible tokens quickly, minimizing latency.
- In thinking mode, ABF reduces the base frequency, allowing more internal reasoning time between visible tokens. This gives the model room for extended chain-of-thought or multi-step reasoning before committing to an output.
In Qwen3, ABF is one of the mechanisms enabling mode-dependent compute scaling.
2. YARN (Yet Another RoPE extensioN Method)
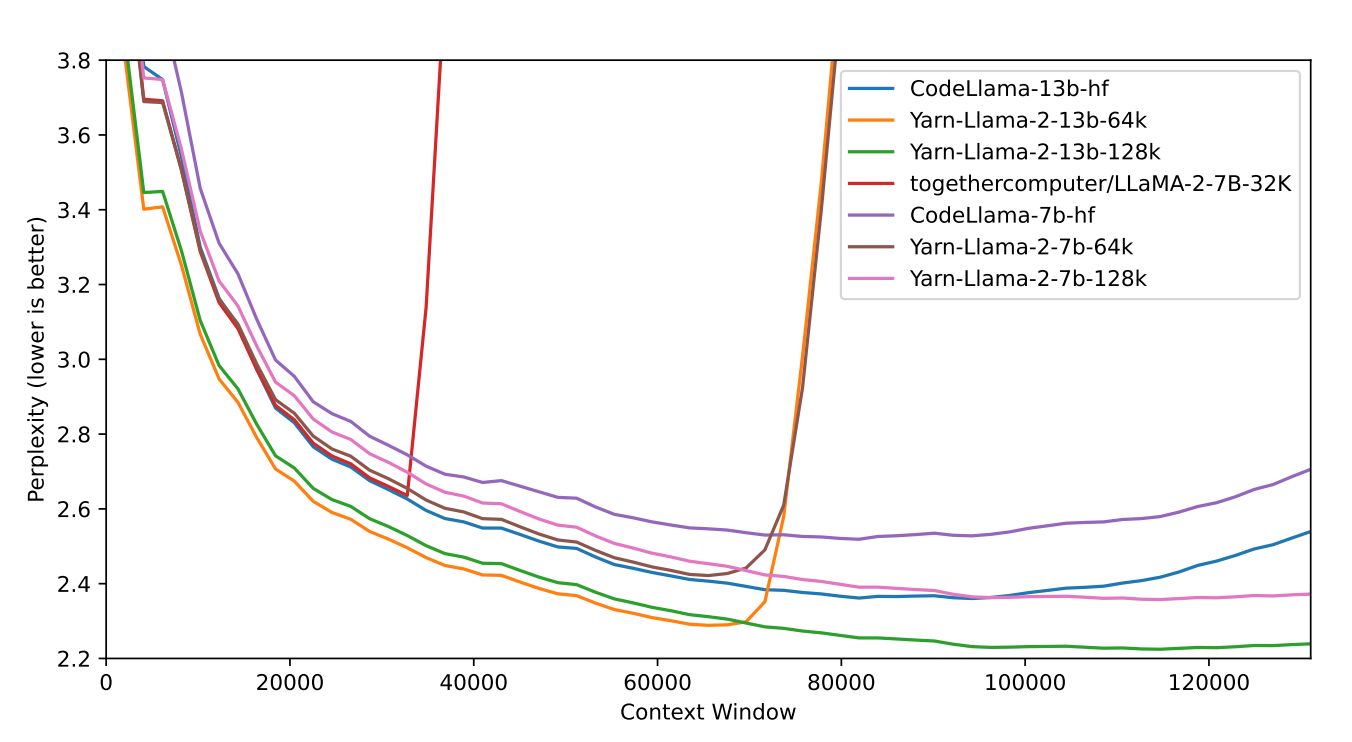
YARN, short for Yet Another RoPE extensioN method, is Qwen3’s approach to handling very long context windows efficiently and accurately.
In transformer models, RoPE (Rotary Position Embedding) is a technique that encodes token positions directly into attention computations, helping the model understand sequence order. However, standard RoPE has a limitation: when you extend the context length far beyond what the model was trained on, its positional understanding degrades — leading to confusion or “attention drift” on long inputs.
YARN solves this by rescaling and adjusting RoPE frequencies so that the model can handle much longer token sequences — from 32K all the way up to 128K or even 256K tokens — without losing accuracy.
In simpler terms:
- Regular RoPE embeds token positions using sine and cosine rotations at fixed frequencies.
- YARN modifies (or “extends”) these frequency scales through a mathematical rescaling trick, preserving positional smoothness even at very large token indices.
- This lets Qwen3 models process extremely long documents, multi-file code repositories, or long conversations while keeping positional relationships consistent.
The result is that Qwen3 and its variants (like Qwen3-Coder and Qwen3-VL) can handle repository-level context or long multimodal sessions efficiently — making them ideal for coding assistants, document analyzers, and agentic reasoning over large input histories.
In short, YARN is the invisible upgrade that allows Qwen3 to see farther without forgetting what came before.
3. Long CoT Cold Start
“Long CoT” means long Chain of Thought reasoning—multistep internal reasoning over many steps. “Cold start” refers to when the model begins reasoning without prior context or scaffolding.
A challenge: if you switch into thinking mode from scratch (cold), the model must bootstrap the chain-of-thought process, without previous internal state. Ensuring the cold start is stable and doesn’t diverge or hallucinate is nontrivial.
Qwen3’s architecture supports this by gating, progressive depth, and ABF: the model may gradually expand reasoning depth rather than jump in full force. This helps it maintain stability in long CoT cold starts.
Also, mixing nonthinking initialization before entering thinking might help warm up internal representations.
4. GRPO (Group Relative Policy Optimization)
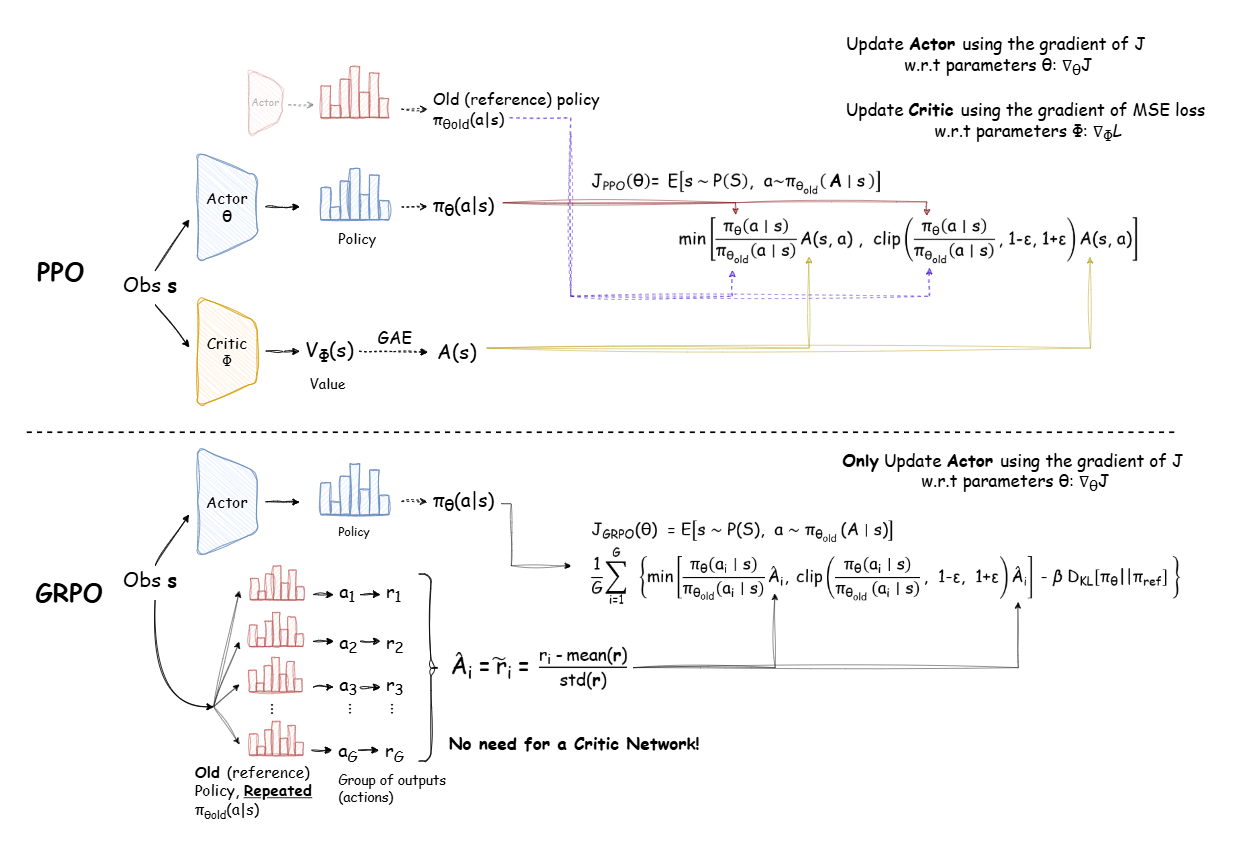
GRPO is a policy optimization method used in post-training to improve reasoning performance. It was used in DeepSeek R1 research and adopted in some applied tuning of Qwen3. The name stands for Group Relative Policy Optimization. The idea is:
- Instead of standard PPO, which optimizes with a single policy and reward, GRPO divides outputs into groups and evaluates relative advantages among them.
- It uses clipped surrogate objectives plus KL divergence penalties to avoid large policy shifts.
- It helps stabilize training where reward signals are sparse or structured (e.g. math correctness).
To summarize, GRPO is a policy optimization technique used during post-training for improving reasoning and correctness.
5. KL Divergence (Kullback-Leibler Divergence)
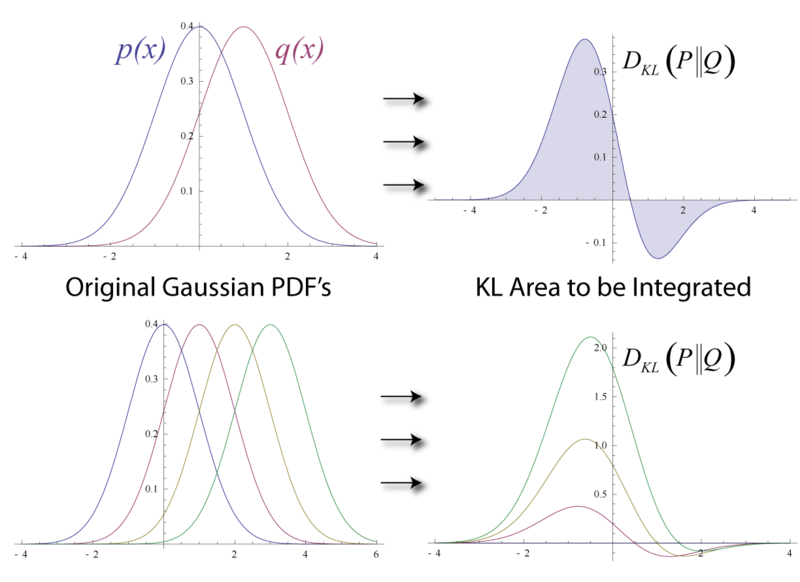
In the context of policy optimization or model tuning, KL divergence is often used as a regularizer or constraint. It measures how one probability distribution diverges from another. In policy tuning (like PPO or GRPO), you don’t want the new policy to stray too far from the original; you constrain the KL divergence between the old policy and the new one.
In Qwen3 post-training (and GRPO specifically), KL divergence is a penalty or clipping bound to ensure stability: the updated policy’s action distribution should not deviate too sharply from the original distribution. This avoids collapses or overfitting to reward anomalies.
In math reasoning tuning, the GRPO objective includes a KL divergence term to stabilize updates.
Hyperparameters: Thinking vs Non-Thinking Mode
Qwen3’s ability to switch between thinking and non-thinking modes also involves adjusting hyperparameters. These parameters control how creative, diverse, or deterministic the outputs are — and how much “thinking space” the model allocates during reasoning.
The general principle is:
-
Thinking mode → deeper reasoning, controlled sampling, more internal computation.
-
Non-thinking mode → faster responses, slightly higher randomness for conversational fluency.
Below is a brief summary of the hyperparameter tuning done across Qwen3 models (as reported in the Qwen3 technical documentation):
| Setting | Thinking Mode | Non-Thinking Mode |
|---|---|---|
| Sampling Temperature | 0.6 | 0.7 |
| Top-p | 0.95 | 0.8 |
| Top-k | 20 | 20 |
| Presence Penalty | 1.5 (for Creative Writing v3 and WritingBench) | 1.5 |
| Max Output Length | 32,768 tokens (extended to 38,912 for AIME’24 and AIME’25 tasks) | 32,768 tokens (extended to 38,912 for AIME’24 and AIME’25 tasks) |
These configurations reflect Qwen3’s balance between controlled reasoning and expressive fluency:
- In thinking mode, the lower temperature (0.6) and higher top-p (0.95) encourage more deterministic reasoning — useful for analytical or multi-step tasks like math, logic, or code understanding.
- In non-thinking mode, a slightly higher temperature (0.7) and lower top-p (0.8) make the outputs livelier and faster, ideal for open-ended conversations or quick answers.
- The presence penalty of 1.5 in writing tasks (Creative Writing v3 and WritingBench) pushes the model to generate more varied and original text, avoiding repetitive phrasing.
- The extended output lengths (up to 38,912 tokens for AIME tasks) give Qwen3 additional “thinking space” — particularly important for long chain-of-thought reasoning or multi-stage derivations.
Examples of Qwen3 in Action
Here are illustrative examples showing how Qwen3 perform on multiple tasks.
Example 1: Full-page OCR for English text
Prompt: “Read all the text in the image.”

Response:
Auntie Anne's
CINNAMON SUGAR
1 x 17,000 17,000
SUB TOTAL 17,000
GRAND TOTAL 17,000
CASH IDR 20,000
CHANGE DUE 3,000
Example 2: Full Page OCR for Multilingual text

Prompt:
Please output only the text content from the image without any additional descriptions or formatting.
Response:
ΠΡΟΣΟΧΗ
ΜΗ ΣΤΑΘΜΕΥΕΤΕ
ΕΔΩ
STOP
ΕΙΣΟΔΟΣ - ΕΞΟΔΟΣ
ΑΥΤΟΚΙΝΗΤΟΥ
G.P
NO PARKING
Example 3: Text Spotting

Prompt:
Spotting all the text in the image with line-level, and output in JSON format as [{'bbox_2d': [x1, y1, x2, y2], 'text_content': 'text'}, ...].
Response:

As we have seen in this section, Qwen3 can effectively process OCR results, extracting and reasoning over textual information from images. This demonstrates its multimodal capabilities in handling real-world vision + text tasks.
We can do much more with Qwen3 across various domains — from long document analysis and code reasoning to planning and complex problem-solving. To explore additional examples and experiments, you can try here.
Summary
Qwen3 sets a new standard in large models by combining strong text reasoning with advanced visual understanding. It performs well on a wide range of tasks—including language, code, math, long documents, and images—without focusing on just one type of input. The model improves visual perception, spatial reasoning, understanding of long sequences, multilingual skills, tool use, and code generation. This allows it not only to “see” but also to understand, think, and take action.
The open-source Qwen3-VL-235B-A22B gives the community a solid base to explore and build on. By continuing to improve multimodal reasoning and long-context abilities, Qwen3 aims to be a helpful assistant that can complete complex tasks.
Thank you so much for reading!