MinerU2.5 Explained: How It Redefines Document Understanding
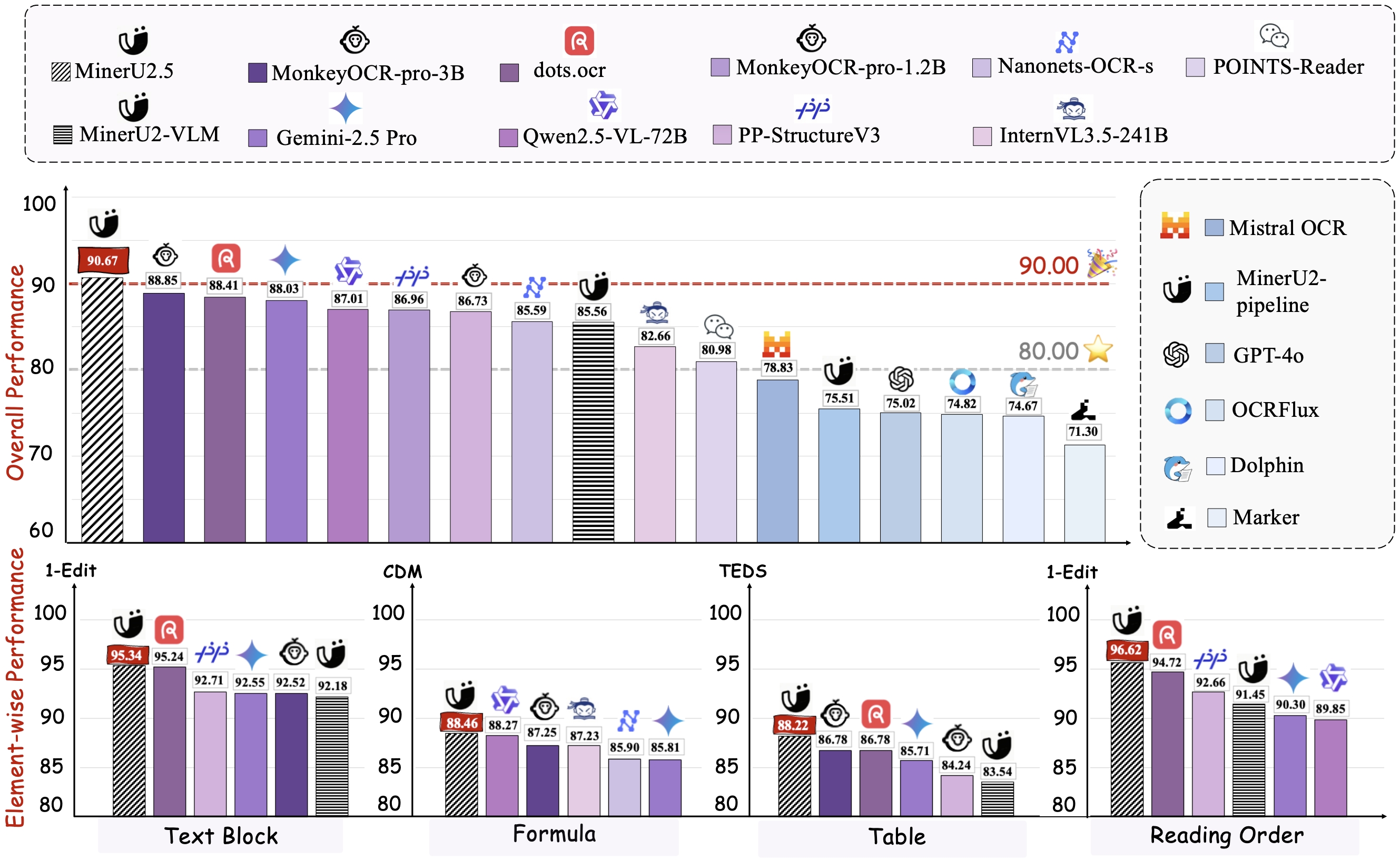
Table of contents
Introduction — What is MinerU?
MinerU2.5 is a new Vision-Language Model (VLM) that can understand and parse complex documents — such as PDFs, scanned reports, textbooks, or research papers — with efficiency.
It has about 1.2 billion parameters, making it lightweight compared to giant models like GPT-4 or Qwen2.5-VL-72B, yet it achieves state-of-the-art results on almost every benchmark for document parsing.
The model was developed by researchers at Shanghai Artificial Intelligence Laboratory. Their goal was to build a model that doesn’t just “read” documents, but truly understands structure and layout, such as identifying text paragraphs, formulas, tables, images, and even reading order.
MinerU2.5 achieves this using a two-stage design:
- First, it analyzes the layout of the whole page at low resolution.
- Then, it recognizes fine details (text, tables, formulas) from cropped high-resolution regions.
This is a simple but powerful idea — by separating the “where things are” step from the “what they contain” step, the model avoids wasting effort on empty spaces and focuses only on the meaningful parts of the document.
Why Do We Need MinerU?
Understanding documents is not the same as analyzing normal photos. A natural image, like a street photo, contains objects spread over a relatively small area. A document, however, can have:
- Extremely high resolution (thousands of pixels tall),
- Dense text filling every inch,
- Tables, formulas, images, and charts, all arranged in structured layouts.
Traditional OCR or AI models struggle with such complexity. They either have to shrink the image (losing fine details) or process massive high-resolution inputs (which quickly becomes computationally expensive).
For example:
- A typical document may contain thousands of small words and symbols.
- A Vision Transformer model would need to create tokens for every patch of the image.
- This leads to a huge number of tokens and slows everything down dramatically.
MinerU2.5 was built to fix this.
- It is designed to retain high detail without wasting computation on blank or low-information regions.
- It can handle large documents efficiently, maintain accuracy, and still run on practical GPU setups.
In short, MinerU2.5 makes document understanding accurate, efficient, and scalable.
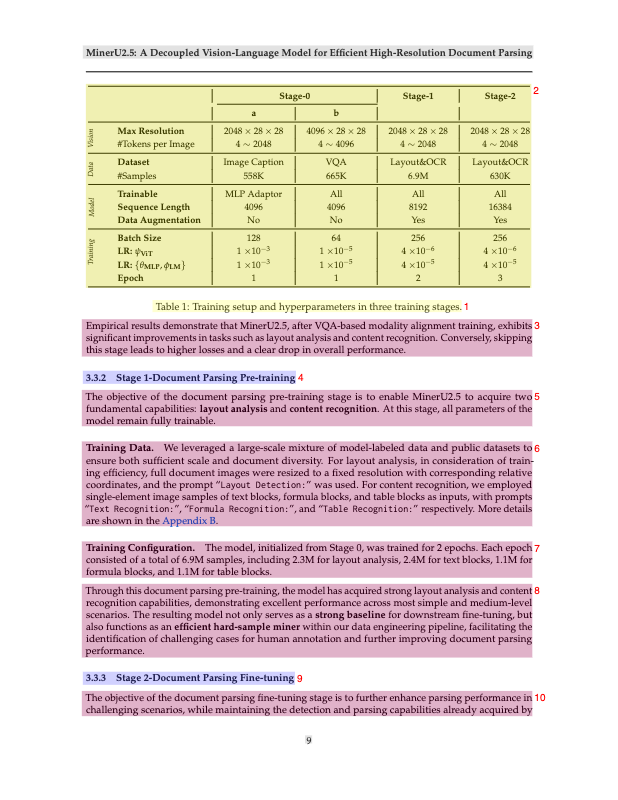
Why Traditional Methods Don’t Work
Before MinerU, there were two main families of document understanding methods:
Pipeline-based Workflows
Older OCR pipelines like Marker, or PaddleOCR used multiple stages:
- Detect layout →
- Recognize text →
- Merge outputs →
- Predict reading order.
Each stage uses a different model or algorithm.
While this approach is interpretable (you can inspect each step), it’s also fragile:
If one step fails (for example, a table is misdetected), the whole pipeline produces errors.
- These pipelines are slow, since each part runs separately.
- They also struggle with multi-column or cross-page structures.
End-to-End Vision-Language Models
The second group includes models like GOT (General OCR Theory), dots.ocr, and MonkeyOCR. These try to process everything in one unified model, often using high-resolution images directly.
While they are elegant, they come with new issues:
- Very high computational cost (O(N²) complexity) because every pixel interacts with every other pixel.
- Memory limits when processing large pages.
- Hallucination problems, where the model generates wrong content or skips sections.
In both cases, the problem comes down to inefficient token usage and entangled processing of layout and content.
MinerU2.5 takes the best of both worlds — it keeps the interpretability of a pipeline but uses the semantic strength of a unified VLM.
The Two-Stage Framework
The key innovation of MinerU2.5 is its coarse-to-fine, two-stage framework.
This approach decouples layout analysis from content recognition, making the model both fast and accurate.
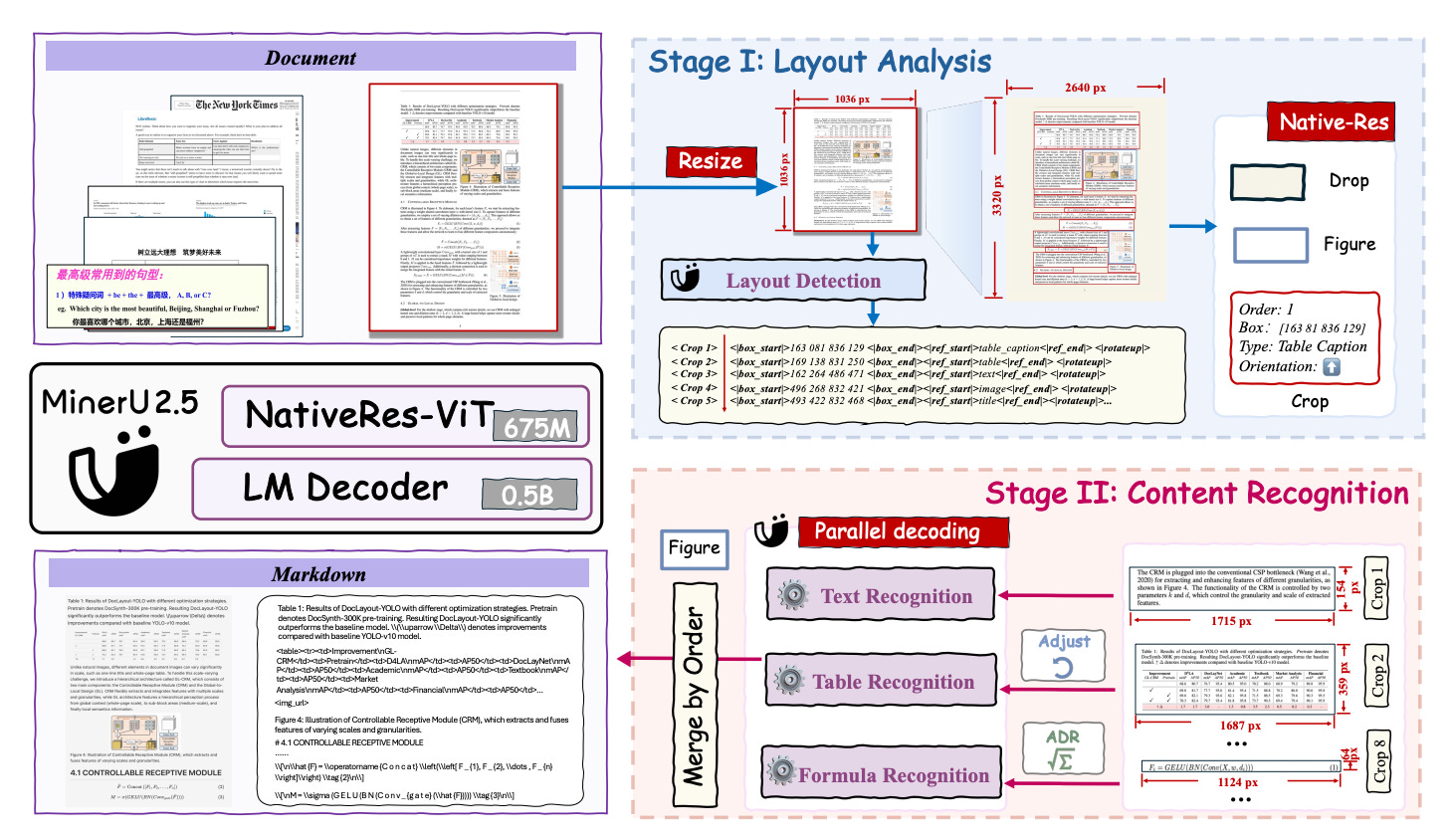
Stage 1 — Layout Analysis (The Global Stage)
In this stage, MinerU2.5 takes the entire document page but resizes it to a smaller 1036×1036 pixel thumbnail. At this low resolution, it performs layout detection — finding where each element is located.
The goal is not to read the content yet, but to get a map of structure: where paragraphs, titles, formulas, tables, and images are placed on the page.
Because the image is small, this step is fast and lightweight, yet it gives a full overview of the page.
Stage 2 — Content Recognition (The Local Stage)
Once Stage 1 finds the coordinates of important regions, Stage 2 crops those regions from the original high-resolution image.
Now, each cropped region (for example, a formula or a table) is sent to MinerU2.5 for fine-grained recognition. This recognition happens at native resolution, meaning all small details like mathematical symbols or thin lines are preserved.
The model then decodes the results — converting text into strings, tables into structured data (HTML or OTSL), and formulas into LaTeX code.
This two-step design allows MinerU2.5 to:
- Skip large blank areas,
- Reduce computation by over 10×, and
- Maintain native-level precision.
The Architecture
MinerU2.5’s design is simple yet effective. It has three main components:
Vision Encoder (NaViT, 675M Parameters)
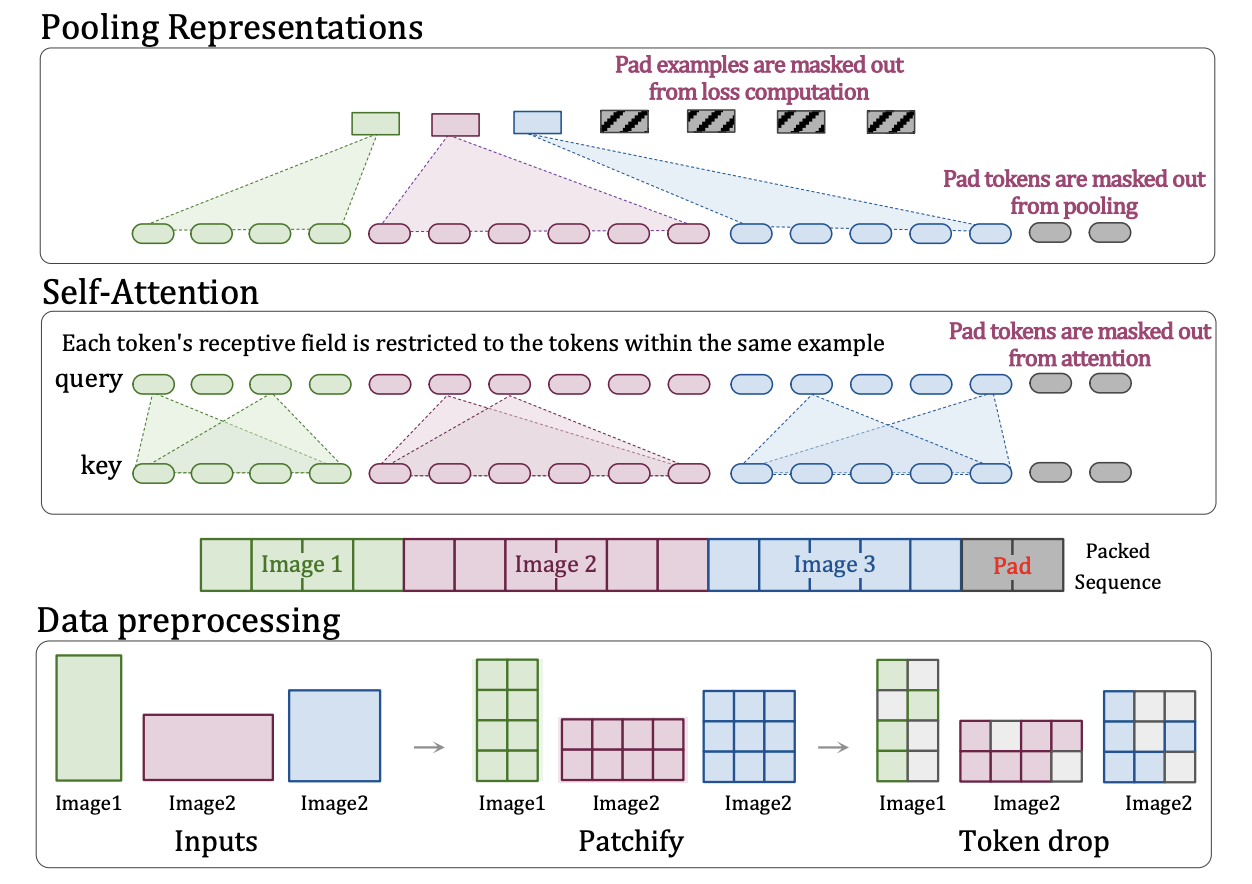
The vision encoder processes the document image. It is built using a Native Resolution Vision Transformer (NaViT), which can handle inputs of different sizes and aspect ratios.
MinerU2.5 uses 2D Rotary Position Embedding (2D-RoPE) inside NaViT. This helps the model understand both horizontal and vertical positions in a document — crucial for reading multi-column layouts, tables, and diagrams.
Unlike “window attention” methods (which split images into small blocks), 2D-RoPE keeps global context intact, so the model doesn’t lose track of how different regions relate spatially.
Language Decoder (Qwen2-Instruct, 0.5B Parameters)
After the vision encoder extracts features, the language model interprets them into readable text or structured formats. MinerU2.5 uses a smaller Qwen2-Instruct model for this, because document parsing doesn’t require large-scale world knowledge — it’s mainly about precision.
This language model uses M-RoPE (Multidimensional Rotary Position Embedding), an improved positional encoding method. Unlike traditional 1D positional embeddings that only handle sequence order, M-RoPE allows the decoder to better generalize across different resolutions and spatial arrangements.
This helps the model recognize text accurately, even if the crop size or image scale changes.
Patch Merger
Before feeding visual tokens into the language model, MinerU2.5 merges adjacent 2×2 image patches using a pixel-unshuffle operation. This reduces the total number of tokens, cutting down computational load while keeping spatial detail.
In essence, it balances speed and accuracy.
Training Strategy
MinerU2.5 is trained in three major stages, each building upon the last.
Stage 0 — Modality Alignment
The first step is to help the model “connect vision with language.” It is trained on Visual Question Answering (VQA) and image captioning datasets like LLaVA-Pretrain and LLaVA-Instruct.
At this point, the model learns:
- What images and text mean together.
- How to respond to image-based prompts.
- Basic OCR-like understanding.
This gives the model a solid foundation before moving into document parsing.
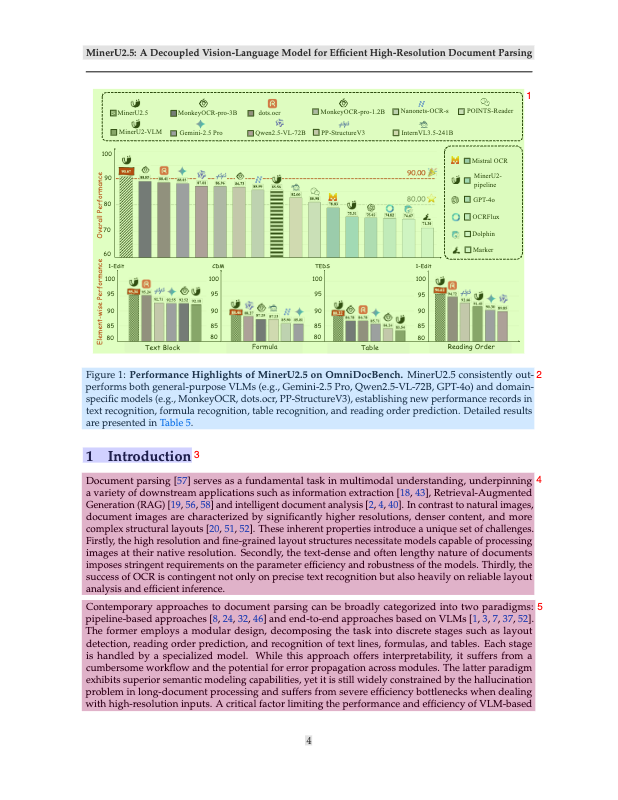
Stage 1 — Document Parsing Pretraining
Now, MinerU2.5 is trained to perform specific document tasks:
- Layout detection,
- Text recognition,
- Formula recognition,
- Table extraction.
The model is trained on millions of examples created using a mix of real and model-generated data. Each type of task uses its own prompt, like:
- “Layout Detection:”
- “Text Recognition:”
- “Table Recognition:”
This teaches MinerU2.5 how to handle different content types in a consistent way.
Stage 2 — Fine-Tuning on Hard Cases
Finally, MinerU2.5 is fine-tuned on challenging examples — rotated tables, multi-line formulas, unusual layouts, or low-quality scans.
The researchers built a data engine to identify where the model still struggles and collect additional labeled examples for those cases.
During this stage, they also used data augmentation such as blur, rotation, lighting variation, and background noise to make the model more robust.
Deployment and Efficiency
MinerU2.5 uses vLLM, an optimized serving engine for large models.
The two stages (layout and recognition) are run asynchronously — meaning while Stage 1 is analyzing page 2, Stage 2 can already start decoding page 1’s crops.
This overlap improves throughput. Dynamic sampling penalties are applied so that repetitive content (like tables) doesn’t get over-penalized.
Results:
- On an A100 GPU, MinerU2.5 processes 2.12 pages per second and 2337 tokens per second.
- That’s 7× faster than dots.ocr and 4× faster than MonkeyOCR-Pro.
- On newer GPUs like H200, it can reach 4.47 pages per second.
This makes it not just accurate, but also production-ready.
Data Engine and Hard-Case Mining
To train MinerU2.5 effectively, the team built a data engine — a pipeline that continuously improves the dataset and model.
The process includes:
- Data Curation – collecting a diverse set of documents across layouts, languages, and types.
- Pretraining Dataset Preparation – generating automatic annotations using older MinerU versions and refining them with expert models.
- Fine-Tuning Dataset Construction – selecting “hard cases” using a special strategy called Iterative Mining via Inference Consistency (IMIC).
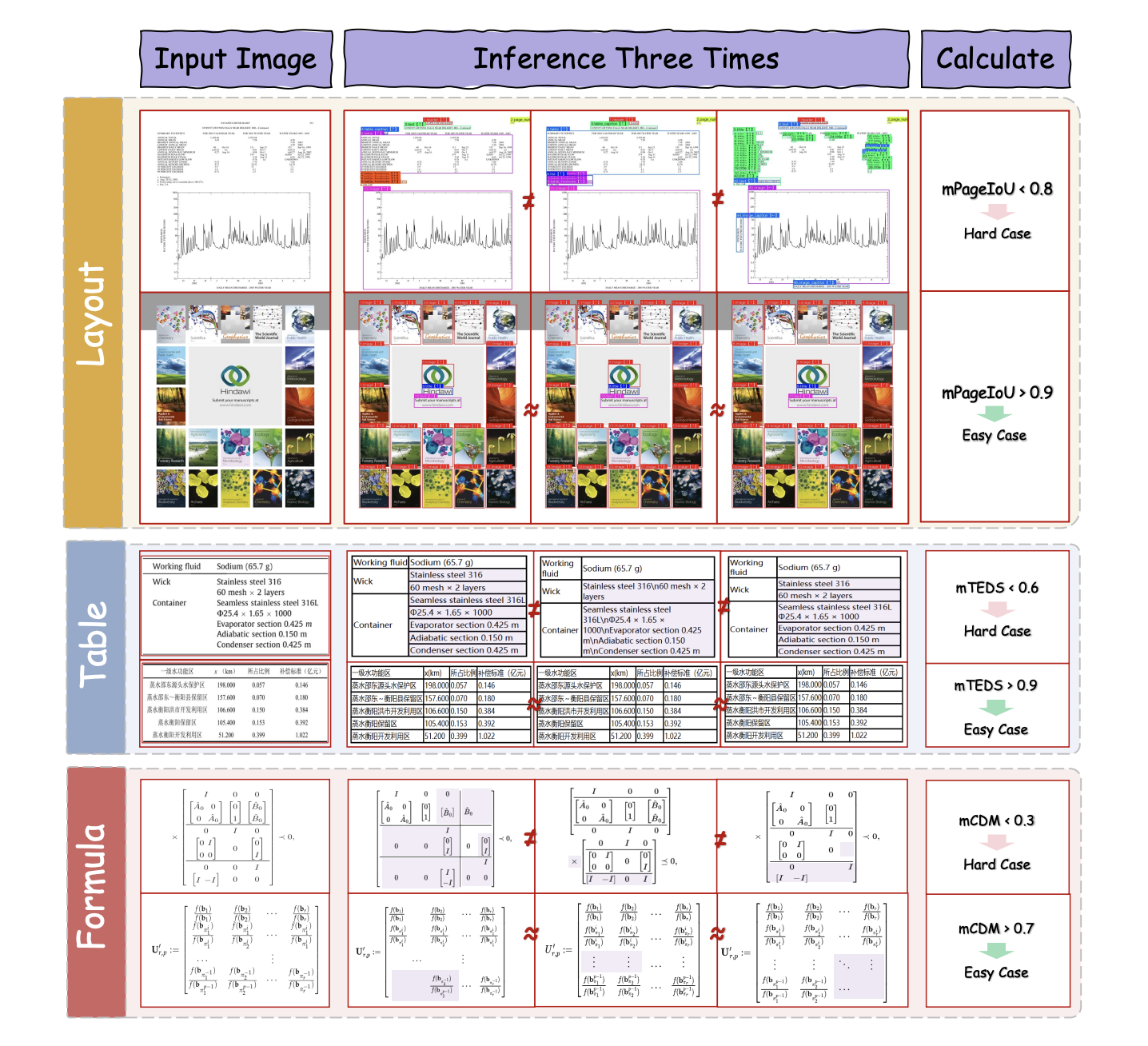
IMIC works by running the model multiple times on the same data. If results are inconsistent (low agreement), those samples are likely difficult cases. Such samples are then reviewed by human annotators for high-quality labeling.
This loop ensures the dataset keeps improving as the model becomes more capable.
Evaluation Results
MinerU2.5 was benchmarked on OmniDocBench, a popular test suite for document parsing.
It outperformed nearly all general and specialized models, including GPT-4o, Qwen2.5-VL-72B, MonkeyOCR, and dots.ocr.
| Model | Parameters | Overall Score ↑ | Formula CDM ↑ | Table TEDS ↑ | Reading Order ↓ |
|---|---|---|---|---|---|
| GPT-4o | - | 75.0 | 79.7 | 67.1 | 0.15 |
| Qwen2.5-VL-72B | 72B | 87.0 | 88.3 | 82.1 | 0.10 |
| dots.ocr | 3B | 88.4 | 83.2 | 86.8 | 0.05 |
| MinerU2.5 | 1.2B | 90.7 | 88.5 | 88.2 | 0.04 |
These results show that MinerU2.5 achieves the highest accuracy while being lighter and faster than any comparable system.
What Makes MinerU2.5 Different
MinerU2.5 introduces several clever techniques worth highlighting:
M-RoPE and 2D-RoPE
These new positional encodings help the model understand where each token is in two dimensions. It’s like giving the model a sense of “left, right, top, and bottom” — not just sequence order.
This is especially helpful for structured layouts such as tables and formulas.
ADR — Atomic Decomposition and Recombination
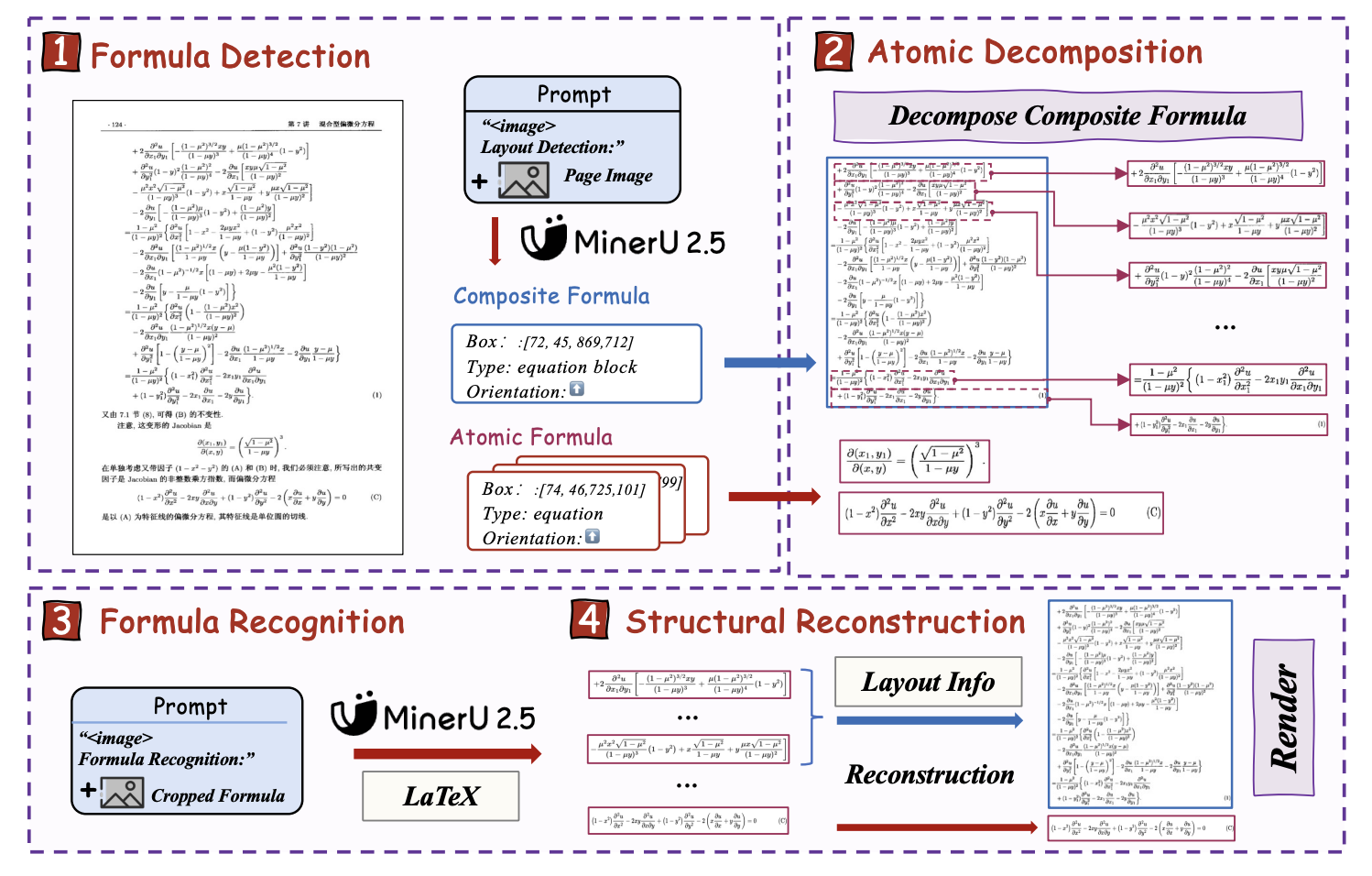
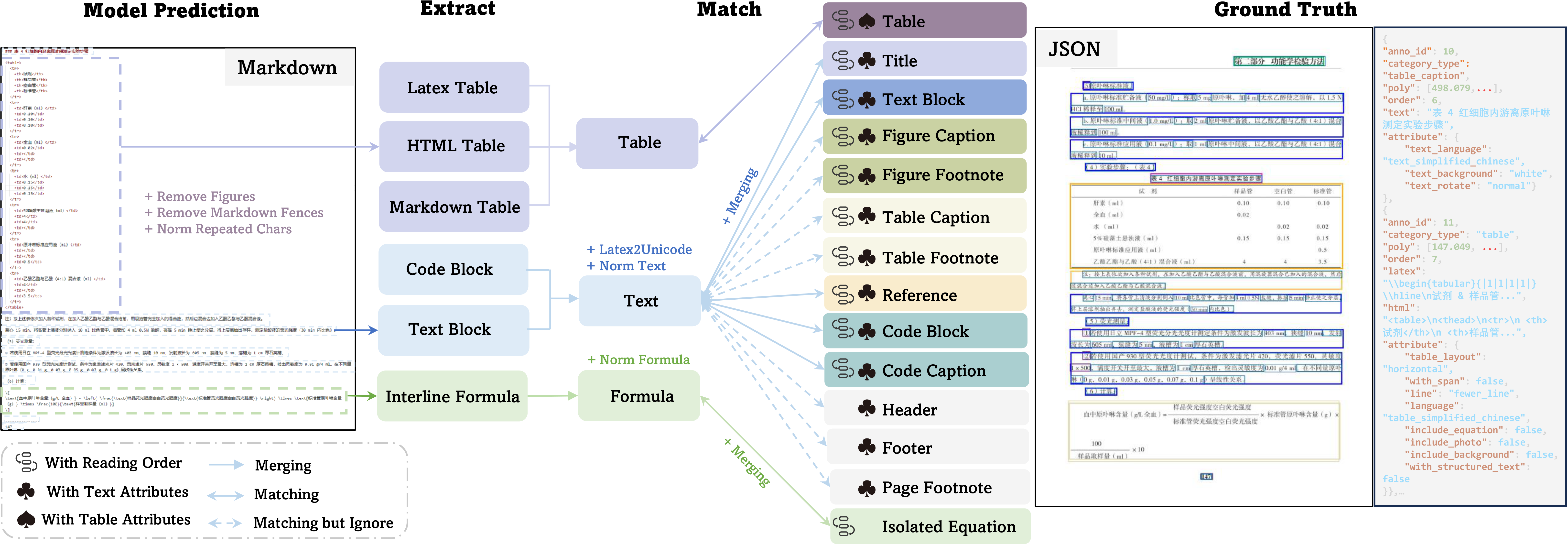
Mathematical formulas are complex, often spanning multiple lines. The ADR framework breaks them into smaller atomic units (simple formulas or expressions). Each is recognized separately and then recombined into LaTeX format.
This prevents errors where large multi-line equations get misread as one long formula.
OTSL — Optimized Table Structure Language
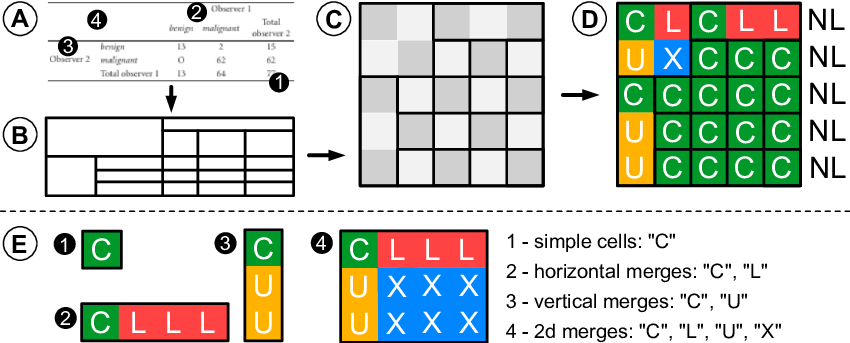
Tables are another challenge. Traditional models use HTML to represent tables, but HTML is verbose and inefficient.
MinerU2.5 uses OTSL, a compact language where a table can be represented with fewer tokens (5 instead of 28). This reduces sequence length and improves accuracy, especially for large or rotated tables.
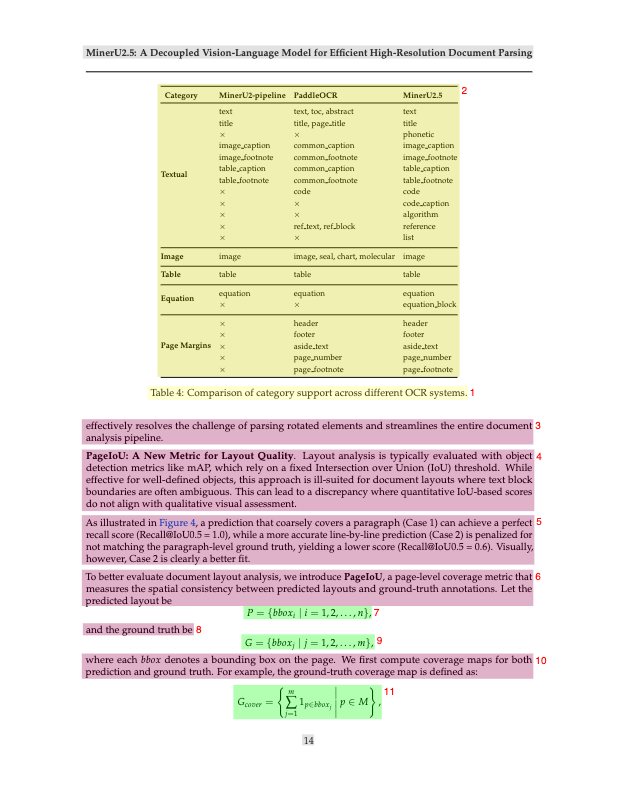
PageIoU Metric
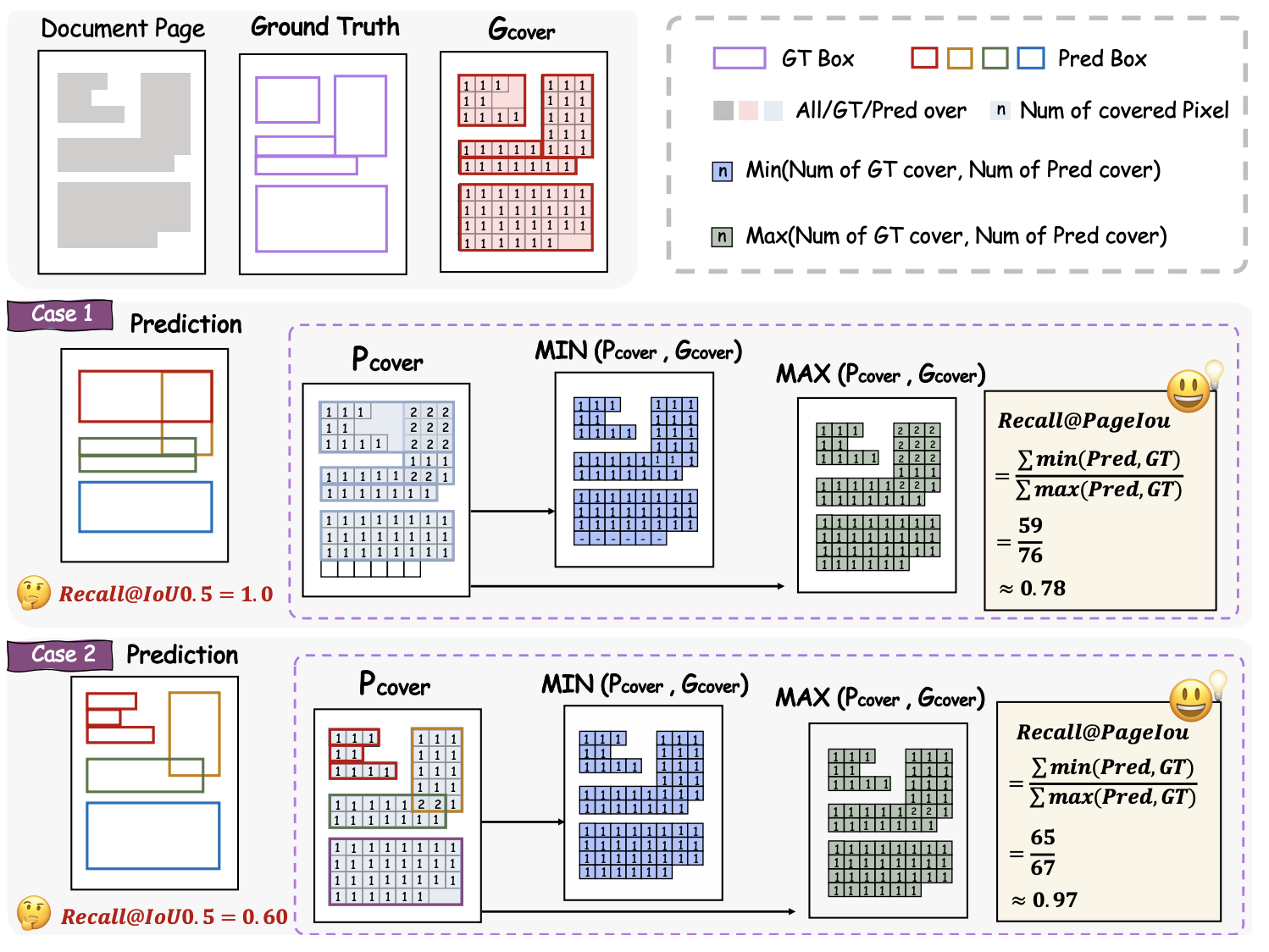
Instead of using normal IoU for layout detection, MinerU2.5 introduces PageIoU — a metric that measures how much of the page’s layout was correctly covered, not just box overlaps. This provides a more human-like assessment of layout quality.
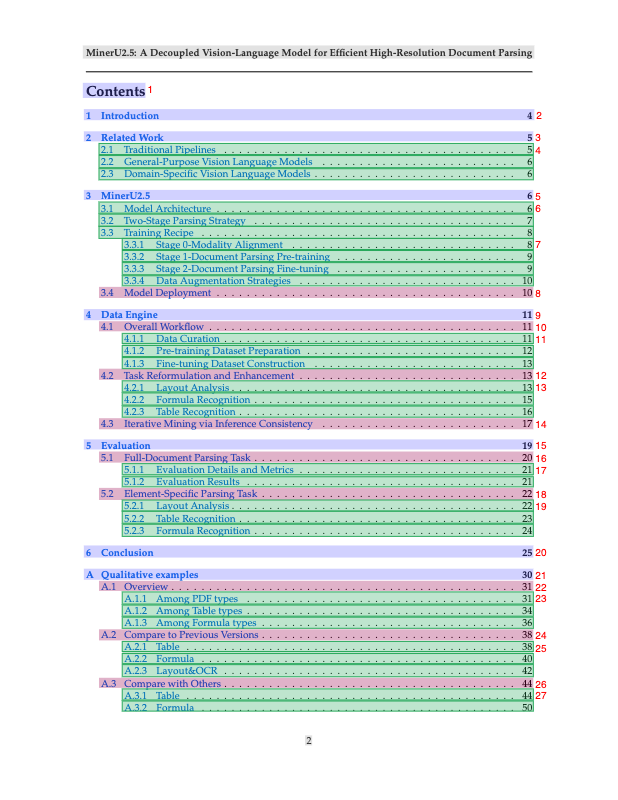
Examples and Visual Results
Next, we’ll walk through some of the examples from MinerU2.5 — showing how it parses academic papers, tables, and images with precise layout detection and efficient text recognition.
Example 1: This image shows MinerU2.5 processing a scientific paper title page, demonstrating its ability to identify title, authors, affiliations, and abstract sections with precise bounding boxes.

Example 2: A visualization of MinerU2.5 analyzing a complex multi-column academic paper with mathematical formulas, showing how it correctly identifies different layout regions and maintains proper reading order.
Example 3: This example demonstrates MinerU2.5’s table recognition capabilities, showing how it accurately parses a complex data table with multiple rows and columns while preserving the structural relationships.
Example 4: An illustration of MinerU2.5 processing a document with mixed content types - text paragraphs, and figure - with color-coded bounding boxes indicating different content categories.
Example 5: This image showcases MinerU2.5’s formula recognition performance, highlighting how it identifies and converts complex mathematical expressions into LaTeX format with high precision.
Final Notes
MinerU2.5 is more than just an OCR model — it’s a complete document understanding system. By combining vision and language reasoning in a smart, efficient way, it can handle everything from textbooks and financial reports to handwritten notes and academic papers.
What makes it stand out:
- High accuracy with fewer parameters
- Fast and efficient two-stage design
- Innovations like ADR, OTSL, and M-RoPE
- Continuous improvement via data engine
It’s available open-source on GitHub and Hugging Face, making it accessible for developers and researchers who want to build document intelligence tools, RAG systems, or multimodal assistants.
MinerU2.5 reads and understands documents the way a human would — first looking at structure, then reading the details — but does it thousands of times faster.